Depuis presque deux ans, je me forme au développement avec des frameworks « Frontend » comme Vue.js (en l’occurrence Nuxt.js) et je me disais qu’une bonne contribution à faire serait de faire un plugin pour pouvoir faire un tel site avec SPIP en backend.
Même s’il existe de multiples solutions en terme de CMS Headless, je viens de passer trois semaines à refondre le plugin collectionjson pour l’adapter aux besoins du développement front.
N’étant pas un grand spécialiste en PHP, ce serait chouette si certains d’entre vous pouvaient faire une rapide revue de code pour vérifier si le plugin présente des problèmes grossiers de performances ou de sécurité.
Merci d’avance pour votre indulgence et vos éventuels feedbacks qui, je l’espère, permettront de faire de ce plugin une contribution utile et fiable à la communauté SPIP.
Juste en passant : c’est une bonne idée. Je ne sais pas qui aura le temps de jeter un œil cela dit, mais avoir la possibilité d’un site statique à partir du BO de SPIP est excellent. Est-ce que tu fournis aussi des templates / un exemple fonctionnel ?
Hello, merci pour ta contribution ! Pas trop le temps et de projet précis pour tester en détail mais ma ptite remarque en voyant l’architecture que tu as choisis :
avoir un SPIP avec une API correcte, headless, peut avoir n’importe quel but : faire un site statique ou autre (l’utiliser en plus comme contenus pour une app mobile, etc, ya plein de cas possibles)
du coup imposer le fait de couper le site public parce que ya cette API, ça me semble totalement deux choses différentes : d’un côté on veut cette API, de l’autre parfois on voudrait couper l’accès au site public OU PAS, c’est totalement séparé
du coup vu que c’est en bonne partie basé sur collection-json (qui est effectivement simple et rapide à comprendre comme structure), ça aurait pu aussi se faire en faisait une branche d’amélioration au plugin existant (qui aurait ensuite été dans une nouvelle version majeure du plugin) avec les histoires de clé etc que tu as ajouté, PUIS dans un deuxième temps totalement déconnecté de ça, avoir un autre plugin, une autre fonctionnalité, qui coupe l’accès au site public (et qui n’a rien à voir avec l’API en soi)
Ça évite les doublons de choses qui font « presque pareil mais pas tout à fait »
Et au passage si des gens utilisent un autre plugin d’API différent (avec une autre structure, autre schéma ou autre format pas json, json-ld ou autre) et bien ces gens pourraient aussi faire un headless sans site public mais avec cette autre API.
Tout pareil: c’est une idée intéressante, et même bienvenue. De même, le manque de temps ne me permet pas d’étudier la question pour le moment. Mais ce serait chouette d’avoir ça en natif dans SPIP5, je trouve !
Je comprends que ce n’est pas évident de mettre son nez dans le code de qqun d’autre. Aussi, pour faciliter la tâche, voici qqes explications.
Toute l’API est gérée par le fichier /http/headless.php. Ce fichier contient, pour le moment, 3 fonctions : get_index (page d’index de l’API), get_collection (page pour une collection) et get_ressource (page pour une ressource). Les deux dernière font appel aux fonctions headless_get_collection et headless_get_objet
En fait, c’est possible de faire un « starter-kit » mais le développement front est très dépendant de la manière dont SPIP est paramétré/utilisé mais surtout du framework front utilisé. Voici un premier exemple avec le framework Astro.
Je m’étais effectivement fait la remarque et tu as raison. Je vais voir pour que l’accès à la partie publique du SPIP soit paramétrable par le webmestre.
J’ai aussi pensé faire un fork (c’en est un en fait). Au départ, le plugin dépendait de collectionjson mais pour faire ce que je voulais, j’ai trouvé plus simple de « pomper » le code et de l’adapter.
Effectivement, ça m’a traversé l’esprit aussi mais je suis parti sur un plugin tout-en-un (paramétrer les collections à exposer, gérer l’exposition des données…) Comme je l’ai expliqué dans le README, l’idéal serait d’exposer un endpoint graphQL qui est devenu plus ou moins le standard pour les frameworks frontend. En attendant de pouvoir faire ça, j’ai fait le choix de mettre en place un format d’API spécifique (sûrement améliorable).
J’ai aussi pensé faire un fork (c’en est un en fait). Au départ, le plugin dépendait de collectionjson mais pour faire ce que je voulais, j’ai trouvé plus simple de « pomper » le code et de l’adapter.
Plutôt qu’une dépendance, ou un fork, je parlais bien d’une branche de proposition d’amélioration du plugin lui-même, donc sans aucune limite de choses à adapter possible, si ensuite on fusionne dans le master pour en faire la nouvelle majeure du même plugin.
(enfin aucune limite en restant dans le cadre du plugin, sans mélanger avec des fonctionnalités séparées comme la suivante dont on parle, bien sûr)
Effectivement, ça m’a traversé l’esprit aussi mais je suis parti sur un plugin tout-en-un (paramétrer les collections à exposer, gérer l’exposition des données…) Comme je l’ai expliqué dans le README, l’idéal serait d’exposer un endpoint graphQL qui est devenu plus ou moins le standard pour les frameworks frontend. En attendant de pouvoir faire ça, j’ai fait le choix de mettre en place un format d’API spécifique (sûrement améliorable).
Ok , c’est sûr que c’est plus facile à maintenir, du tout-en-un !
Après dans SPIP on est plutôt du genre « surtout pas tout-en-un », et tenter au maximum de réfléchir en modulaire, en ne mélangeant pas dans un même plugin des fonctionnalités sans rapport technique (même si end user ça peut être en lien), afin justement de laisser le choix de quoi utiliser ou pas.
(là en l’occurrence le fait de bloquer l’accès au public n’a pas de lien technique particulier avec telle API précise, ça pourrait être utile à utiliser avec n’importe quelle autre API, et même sans API du tout, pour les gens qui utilisent la base de contenu en « base externe » dans un autre SPIP ailleurs par ex).
Oui. Tout fait d’accord avec ça. C’est pour ça que j’étais en train de me demander quelle solution pratique permettrait de couper facilement (par une case à cocher par ex) l’accès à la partie publique de SPIP à un webmestre. Le plugin SPIP RESET renvoie une 404 si pas de squelettes. Mais là, on voudrait complètement couper l’accès, même s’il y a un squelette. Existerait-il un plugin qui fait déjà ça ? Sinon quelle méthode serait la plus élégante pour en faire un ?
Dans l’idéal effectivement, il faudrait un (ou plusieurs) plugin(s) qui gère(nt) l’API ou les APIs (graphQL, JSON ou autres) et un autre qui, éventuellement, bloque l’accès à la partie publique.
Finalement, je pense faire une branche sur le plugin collection_json et apporter ma contribution dedans. Est-ce que cela vous convient comme manière de faire ? Par contre, ça va faire du gros BREAKING CHANGE quand ça va merger !
vu comme il a pas bougé depuis un bail c’est pas super grave… du moment qu’on change bien le X majeur
après faut juste pas perdre en fonctionnalités, et pas casser inutilement des choses qui peuvent être gardées (genre là laisser le même nom d’action/api si on reste bien dans le même plugin sans fork), mais à discuter des détails dans la PR
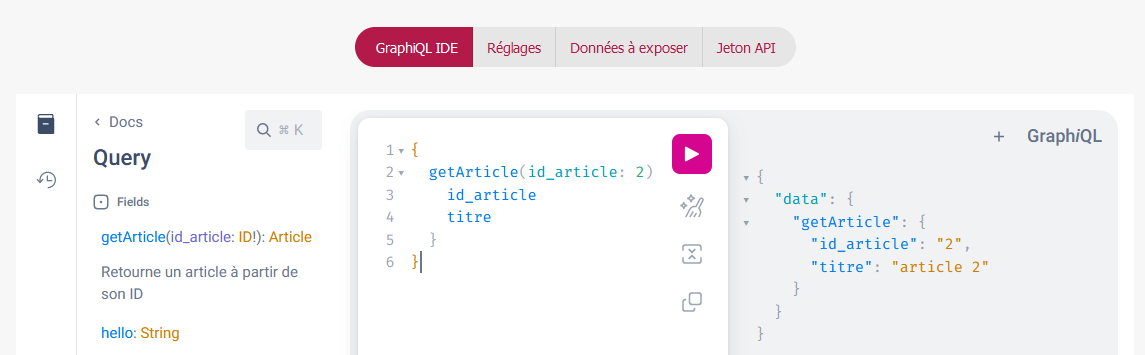
Éventuellement, pour ceux que ça intéresse, je viens d’échafauder le début d’un plugin pour exposer du graphQL et j’ai réussi ma première requête graphQL sur un SPIP !
Plutôt que de forker un plugin qui expose du json (le besoin est déjà rempli avec ezrest et collectionjson), autant faire qqe chose qui n’existe pas. Donc, je me concentre sur celui-ci et si y’a des intéressés, les coups de main sont les bienvenus. Quand, je vois le nombre de contributeurs et de soutiens pour l’équivalent Wordpress, c’est impressionnant.
FEATURES :
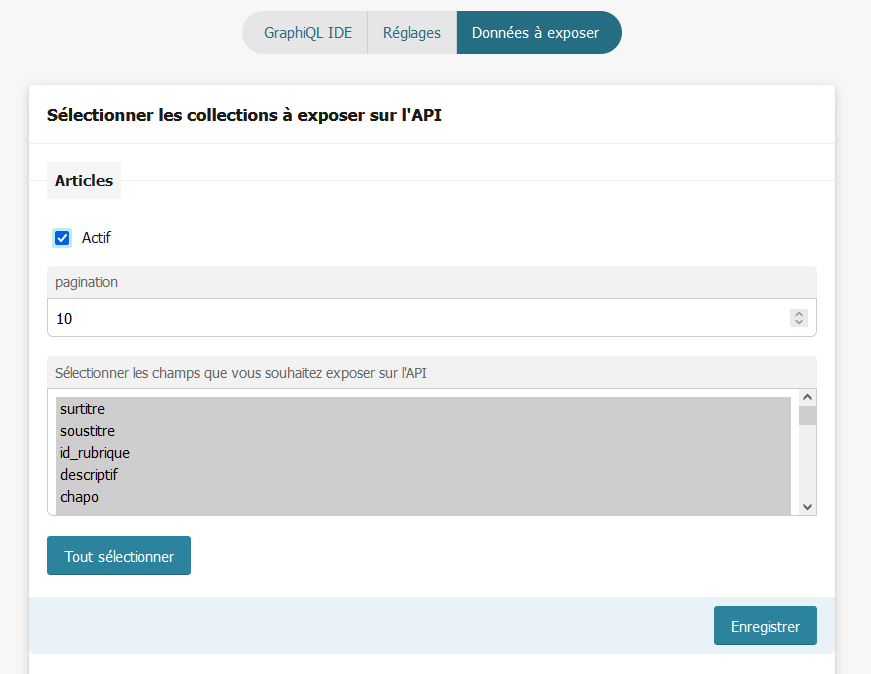
Sélection des objets et des champs à exposer dans l’API (ainsi que les metas)
Génération dynamique du fichier représentant le schéma d’introspection de l’API graphQL (pour n’exposer que les données sélectionnées)
Génération d’un fichier de cache pour optimiser les requêtes
Sécurisation par jeton API
Mode debug pour remonter les erreurs PHP dans la réponse
TODO :
Gérer les liaisons SQL entre les objets
Mettre en place une/des requêtes pour utiliser la recherche SPIP
J’ai pas suivi le fil complet mais en lisant le dernier post je n’arrive pas à voir ce qui est différent de ezREST et surtout ce qui t’aurais empêché de repartir de ezREST pour batir ton plugin.
Ce que je vois c’est qu’il faut un mécanisme pour définir par configuration les collections exposées, ce qui est possible dans ezREST.
la génération de cache est incluse dans ezREST
la sécurisation de l’API aussi
et le mode de debug est facile à intégrer puisque tu as la main via des fonctions de services dessus.
Pour moi tu n’avais qu’à coder les fonctions de services de tes collections et c’est tout.
Oui tout à fait. J’utilise d’ailleurs ezrest pour ce projet. Mais là je voulais pouvoir faire du graphQL. Aucun plugin n’existe dans l’écosystème SPIP.
Ah bon ? Le webmestre peut sélectionner les champs à exposer dans le Back-Office avec le plugin ezrest ?
J’avais fait un 1er développement pour faire du JSON en partant de collectionjson (pour les raisons invoquées plus haut). Suite à tes retours, j’allais peut-être forker collectionjson. Mais :
Parce qu’il y a encore des fonctionnalités que j’aimerais implémenter avant de le mettre dans CONTRIB. Je me laisse encore une semaine. Après, va falloir que je courre chercher des euros pour payer le loyer
Et puis, je cherche encore la meilleure façon de créer le schéma d’introspection. Je crois que mes connaissances en PHP sont trop limitées. Le point qui me bloque un peu c’est comment créer des classes PHP dynamiquement. Je n’ai pas réussi à trouver de solution fonctionnelle. Donc, pour le moment, je génère un fichier SDL (schema.grapqhql) lors de l’enregistrement des collections et des champs à exposer. Puis, lors de la première requête, le plugin crée un fichier cached_schema.php qui permet de construire le schéma plus rapidement (voir la doc). Le problème, avec cette solution, c’est qu’il faut mettre en place un TypeRegistry pour dire à graphQL le type de retour attendu dans les resolvers. Enfin, j’en suis là Mais si y’a moyen de créer des class PHP dynamiquement, à mon avis c’est la meilleure solution.
Et bah voilà qui est fait ! Cette solution est techniquement la bonne en terme de performances et ça m’a débloqué pour terminer les 2 fonctionnalités que je voulais implémenter : la recherche et les liaisons entre objets. La classe SchemaSPIP utilise le pattern TypeRegistryexpliqué dans la doc de la lib ce qui permet de créer les types et les requêtes à la volée sans limitations.