Je viens de pusher qqes correctifs. Le plugin est fonctionnel à 90% (Je voudrais implémenter les relations SQL 1=>N). Pour la doc, a priori, y’a à peu près tout dans les README (là et là). J’ai pris un soin particulier à la rédiger ainsi que les commentaires directement dans le code. Mais si qqun veut contribuer et a besoin d’éclaircissements, je peux aider 
Oui bien sûr, mais faut pas pousser mémé dans les orties, laissons le temps à @paidge de terminer de coder son plugin ![]()
1 « J'aime »
Surtout que c’est un comble qu’on me demande ça quand je vois que 80% des plugins SPIP ont un README complètement vide. Même si certains ont une page d’explication sur un des sites de l’écosystème. Pour moi, ça me paraît la base. Quand je tombe sur un dépôt SPIP, je n’ai, en général, pas une seule info  ça n’enlève rien à la valeur de tout ce qui a été fait. C’est juste que l’écosystème PHP/SPIP, c’est là où je passe le plus de temps à chercher qu’à coder ^^ Donc là, j’ai passé (beaucoup) de temps à rédiger de la doc (presqu’autant qu’à chercher comment faire ci ou ça avec SPIP. C’est dire lol). La moindre des choses c’est ptet de la lire Mais je répète : je suis prêt à faire une visio ou autre pour en parler si des personnes sont intéressés par graphQL. C’est le meilleur système d’API que j’ai rencontré pour développer du front avec un framework Node.js (Angular, React, Vue, Astro…)
ça n’enlève rien à la valeur de tout ce qui a été fait. C’est juste que l’écosystème PHP/SPIP, c’est là où je passe le plus de temps à chercher qu’à coder ^^ Donc là, j’ai passé (beaucoup) de temps à rédiger de la doc (presqu’autant qu’à chercher comment faire ci ou ça avec SPIP. C’est dire lol). La moindre des choses c’est ptet de la lire Mais je répète : je suis prêt à faire une visio ou autre pour en parler si des personnes sont intéressés par graphQL. C’est le meilleur système d’API que j’ai rencontré pour développer du front avec un framework Node.js (Angular, React, Vue, Astro…)
1 « J'aime »
Oups désolé si j’ai heurté. Dans la mesure où @paidge nous confiait n’avoir plus que peu de temps à consacrer à ce thème, je voulais rappeler l’avis d’un utilisateur potentiel. Et si comme moi tu es sensible au fait qu’il manque des docs pour de trop nombreux autres plugins, je pense que tu peux comprendre.
1 « J'aime »
Je comprends tout à fait C’est juste que je me disais que tu n’avais même pas pris le temps d’aller voir le dépôt. Mais comme effectivement il n’y a jamais rien dans les readme, je comprends que tu n’aies pas pris le temps d’aller jeter un oeil ^^
Bon bah voilà le plugin fonctionnel (enfin je crois Il y a sûrement des cas particuliers que je n’ai pas testés). N’hésitez pas à faire joujou avec et à remonter les bugs éventuels L’idéal pour tester les limites, c’est d’avoir des objets éditoriaux qui ne sont pas fournis dans le coeur et des champs extras
L’autre jour sur IRC je demandais :
ya pas mal de trucs « en dur » à ce que je vois, genre là pour récup les champs, ça fait des opérations différentes suivant les noms des champs, mais c’est arbitraire en dur et sans pouvoir surcharger pour tel autre type où on voudrait renvoyer autre chose non ?
par ailleurs ya qu’une manière de récup une collection, par where SQL « brut » uniquement ? donc impossible de profiter des automatismes/facilités/optimisations des boucles SPIP ? (dans collection json par ex on pouvait renvoyer la réponse d’une collection soit en fonction PHP donc en faisant du SQL à la main, soit en squelettes donc en profitant des boucles). Un exemple typique : les filtres complexes de « distance » ajoutés par GIS. Ya plusieurs critères comme ça qui sont pas des basiques truc=machin super simples. Ou encore les critères qui génèrent des jointures (et parfois plusieurs avec table de liens entre les deux), quand ya pas forcément id_auteur ou autre direct dans les champs de la table (« les articles de l’auteur 3 » ou « tous les documents liés à la patate 4 »)
de plus j’ai pas trop compris la séparation dans une requête différente pour la recherche car généralement dans SPIP (et dans les API qui en découlent) la recherche libre c’est juste UN filtre possible parmi d’autres qu’on peut permettre sur les « collections » justement… càd que quand je requête « les articles » je peux alors réduire que la branche de la rubrique 3 ET faire une recherche libre aussi ET tout autre filtre (genre « les articles de la branche 3 qui ont le mot « prout » dedans et qui sont à moins de 3km de tel point central »)
voilà dans les trucs qui m’intéressent (où moi c’est pas tant « comment l’utiliser » mais comment rendre possible en tant que dev les requêtes/filtrages que je veux, et en renvoyant les champs que je veux avec les formatages que je veux) 
Oui j’ai vu ton commentaire sur IRC et j’y ai répondu. Voici ma réponse plus complète :
Je ne vois pas trop l’intérêt de surcharger les réponses par squelette étant donné que le plugin propose au webmestre de choisir les collections et les champs à exposer. A moins de vouloir créer des requêtes précises.
Je ne sais pas si c’est possible via un squelette. Il faut pouvoir répondre à des requêtes de ce type :

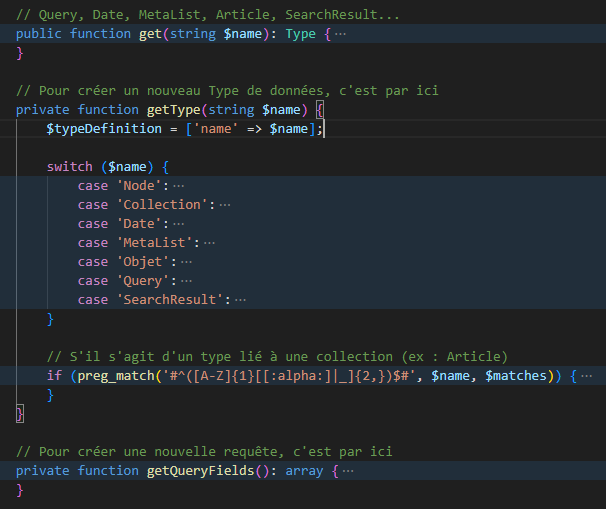
Les requêtes sont des champs (fields) d’un objet GraphQL\Type\Definition\ObjectType dont le nom est Query. A moins que mes connaissances en PHP (et surtout en SPIP) me permette d’entrevoir une solution, je ne vois pas trop comment faire. Il faut que le serveur interprète la requête graphQL, vérifie les types puis fournisse une réponse adaptée, correspondant aux types. Mais si des SPIPeurs ont une solution, j’ai mis le plugin sous licence GPLv3 (même si le fichier licence n’apparaît pas  )
)
Le plus dur, c’est de rendre ça le plus dynamique possible - comme tu l’as si bien remarqué - pour pouvoir s’adapter aux différents objets éditoriaux qui seraient fournis par des plugins, aux différents types de champs (transformer les types SQL en types GraphQL) et gérer les liaisons entre les tables. J’ai essayé avec lister_table_objets_sql() mais, par ex, pour le plugin pensebete (qui me sert de test pr les objets éditoriaux non standards), bah j’arrive pas à savoir à quelle table correspond le champ id_donneur. Y’aurait ptet des possibilités avec des librairies comme Doctrine mais je ne m’y connais pas assez (j’ai eu une formation sur Symfony y’a 10 ans lol).
Je rappelle que j’ai des connaissances assez basiques en PHP. Ma seule contribution à l’écosystème SPIP (et même PHP) c’est le plugin TarteAuCitron qui, pour mon plus grand bonheur, est maintenu par des personnes qui l’utilisent (le projet pour lequel il était destiné n’a même pas vu le jour  )
)
Donc, si jamais certains d’entre vous souhaitent contribuer pour améliorer le code (et c’est sûrement nécessaire) ça pourra améliorer la robustesse du plugin et m’apprendre sûrement des bonnes pratiques PHP/SPIP pour des projets futurs Ou alors, tu me dis comment je peux améliorer ça et je le fais si j’ai le temps Même pour un array_merge, je cherche dans la php-doc pour vérifier si je l’utilise correctement alors ça me prend un temps fou ^^ Je crois que le pire c’est la doc de référence des saisies
Je serais très heureux de partager avec ceux que ça intéresse les connaissances que j’ai accumulées sur le développement de ce projet Par Discord ou autre Jitsee-like.
Justement, un des buts de ce plugin c’est de permettre, en tant que dev (« back »), d’exposer les données d’un site pour un dev « front ». Ce qu’il a besoin (le dev front) c’est de pouvoir récupérer les infos nécessaires pour les afficher dans son site/son appli. Et, pour le coup, l’appli est suffisamment dynamique pour répondre à ce besoin. Le webmestre peut sélectionner uniquement les infos à exposer pour le front. Ca marche avec les champs extras et aussi les objets éditoriaux non-standards ^^
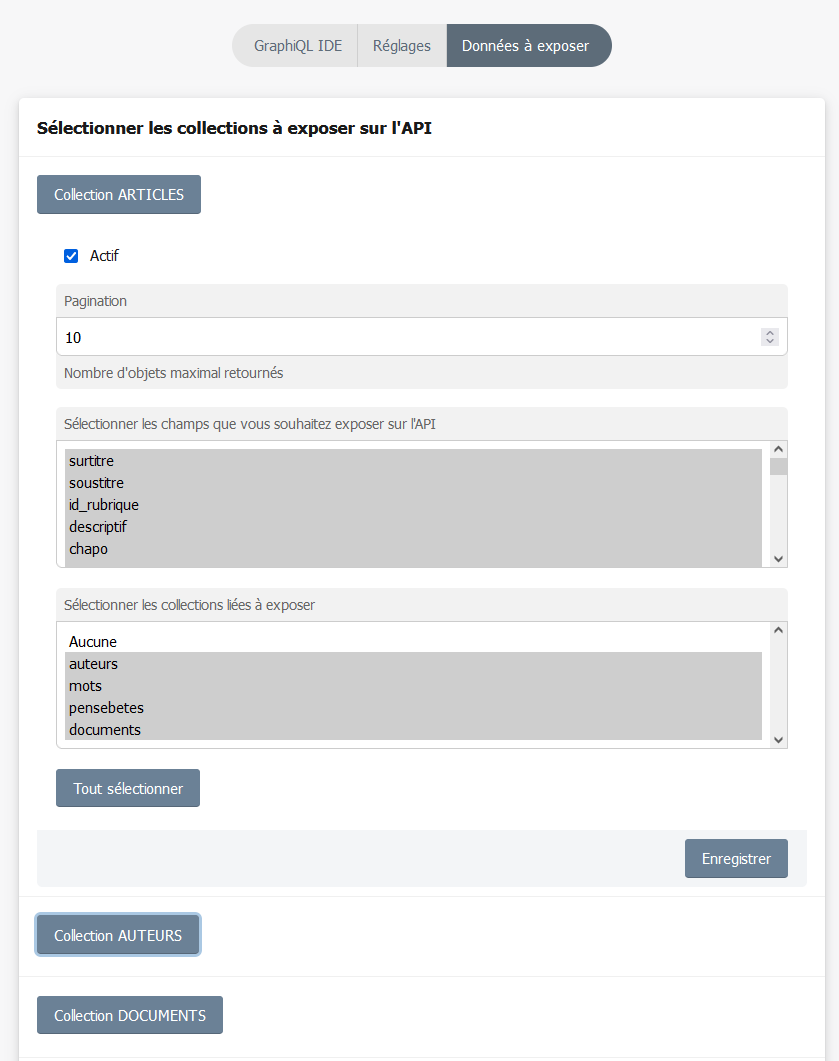
Là, où je te rejoins c’est qu’il pourrait y avoir des pipelines ou des truks du genre pour customiser le fonctionnement du plugin. Pour le moment, ça couvre les besoins les plus courants (récupérer une liste d’objets avec des critères sur les champs, récupérer un objet en particulier et les objets qui y sont reliés, faire une recherche ciblée sur un type d’objet ou sur tous les objets, etc.). A mon avis les meilleures contributions seront celles qui rendront le plugin le plus dynamique possible sans que le dev n’ait besoin de coder quoi que ce soit. (cf l’équivalent pour Wordpress cité plus haut)
Après réflexion, c’est ptet possible si la réponse fournie par le squelette respecte le schéma d’introspection généré (le schéma est généré par rapport aux sélections du webmaster dans les réglages du plugin). Il faudrait que le squelette analyse la requête (que celle-ci doit valide le schéma) et fournisse une réponse valide avec le schéma. Par contre, pour créer une nouvelle requête, celle-ci devrait être exposée dans le schéma avec ses types graphQL en entrée (éventuellement) mais surtout en sortie. Et là je sèche un peu.
Sinon, j’ai testé un peu mon plugin ![]() et le champ id_trad pose problème (j’ai ptet mal saisi son utilité). J’ai aussi identifié les besoins suivants :
et le champ id_trad pose problème (j’ai ptet mal saisi son utilité). J’ai aussi identifié les besoins suivants :
- renvoyer le numéro de page et le nbre de pages en cas de pagination
- avoir la liste des articles pour une rubrique
- la liste des objets liés pour un mot-clé
- la liste des mots dans un groupe
Je t’en donnais plus haut du même genre qui sont parfaitement courants, les contenus de type XXX d’un auteur, ou en fait toute autre liaison indirecte dont le champ n’est pas directement à l’intérieur de la table, comme les docs d’un contenu précis, etc, tout ce qui a une table de lien (et des fois la jointure est plus complexe qu’une seule table de lien). Ou les critères dynamiques ajoutés par des plugins comme le distance de GIS (les patates situés à moins de 3km d’un point).
Une API que ce soit graphql ou autre c’est pas forcément que pour faire un site statique (donc quasiment toujours très basique), mais aussi pour des apps, du mobile, etc, et qui doivent pouvoir filtrer selon les mêmes filtres que ce qu’on sait faire en boucle.
C’est sûr que quand on fait un site statique, généralement dedans ya pas de formulaires, donc pas de filtrages possibles genre facettes, carto, etc. Mais là c’est pas un plugin « site statique » c’est un plugin « graphql » donc ça peut être pour n’importe quoi.
Pour ce qui est du squelettage, moi je pensais pas que c’est à un squelette de générer le contenu complet, mais le fait des sélectionner les résultats de l’objet racine qu’on demande (les articles par exemples), et ensuite ça donne une liste d’ID et c’est à une autre fonction de générer « l’intérieur » des champs à renvoyer (avec un truc par défaut, et là aussi possiblement une fonction/classe détaillée si on veut surcharger pour faire un truc à soi).
1 « J'aime »
Hello,
Ouais c’est pas mal cette api GraphQL comme alternative à REST.
Je vais essayer le plugin pour mieux apprécier la différence car pour l’instant c’est un peu flou pour moi coté utilisateur.
Par contre, ce que je perçois, peut-être à tort, c’est que ça renvoie quand même la complexité sur le client, mais bon ça reste à tester.
En tout cas bravo pour la mise en oeuvre rapide.
1 « J'aime »
Pas forcément, tu peux avoir un site front (en PHP/JS, ce que tu veux) qui va taper l’API de ton back et générer les pages côté serveur malgré tout. Mais tu peux aussi faire le rendu dans le navigateur, tout dépend des besoins.
Bonne idée ce plugin ![]()
1 « J'aime »
Justement, ça j’y arrive sans problèmes ![]() A moins que je n’ai loupé qqe chose, il est plus aisé de deviner une table intermédiaire qu’une liaison directe. Je n’arrive tjrs pas à deviner à quelle table correspond le champ
A moins que je n’ai loupé qqe chose, il est plus aisé de deviner une table intermédiaire qu’une liaison directe. Je n’arrive tjrs pas à deviner à quelle table correspond le champ id_donneur pour le plugin pensebete par ex.
C’est effectivement le but.
Je ne vois pas trop ce que tu veux dire car je ne connais pas ces plugins mais je ne vois pas ce qui serait bloquant car on peut filtrer au niveau de la requête et de la réponse.
Pour le squelettage, j’ai qqes idées que je vais essayer d’implémenter.
Tu peux tester les requêtes directement dans le plugin via le client graphiql. Sinon via un client que tu installes en extension firefox (voir le README). Personnellement, je n’ai codé que des clients en Vue.js utilisant, par ex, la bibliothèque Apollo. Mais comme le dit dit si bien, @cpol0 : c’est possible de faire un client dans n’importe quel language, y compris en PHP (des bibliothèques existent).
Il ne faut pas exclure la possibilité que le plugin pensebête ne respecte pas totalement les recommandations SPIP sur la manière de dresser la table au mieux (la fourchette à gauche ou à droite ?) car ça peut fonctionner même sans ce respect (mon fils assure mordicus qu’il faut manger les frittes et la pizza sans fourchette).
Il serait à mon avis préférable de t’appuyer sur un plugin dont l’auteur fait partie de la team. Je ne peux t’en recommander un en particulier mais peut être quelqu’un pourrait.
C’est ce qu’il me manque : obliger les devs à bien déclarer leurs tables et leurs liaisons Si le cœur de SPIP permettait de clairement formaliser les liaisons entre les tables SQL, même celles créées par des plugins, ce serait vachement plus pratique
Mise à jour « importante » (passage en 0.2.0) avec un type Interface Objet qui prend en compte tous les types d’objets et leurs liaisons (quand elles sont déclarées ), exposition de la pagination et ajout d’un plugin pour le client intégré afin de construire ses requêtes plus facilement :
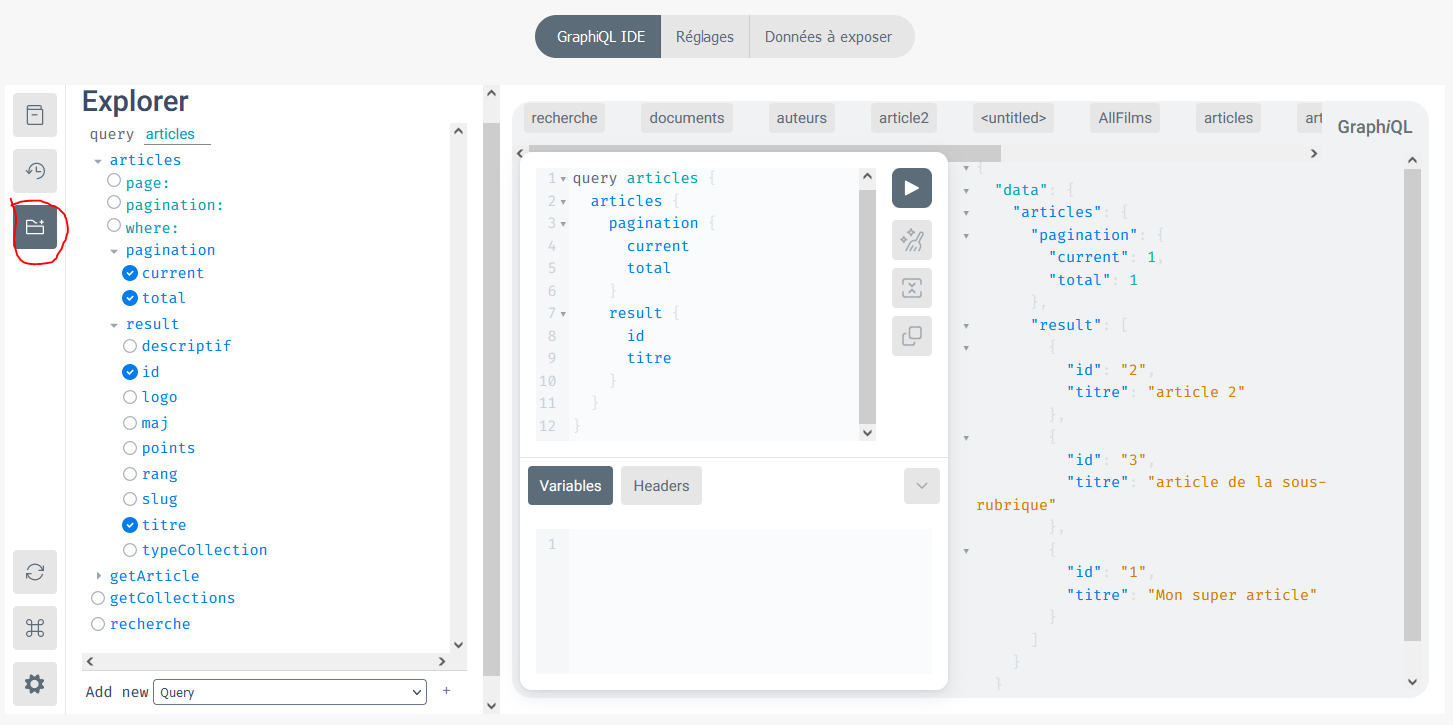
Quand j’utilise $infos = lister_tables_objets_sql($maTable), le champ $infos['parent'] est parfois rempli parfois vide (j’ai compris que c’était normal). Par contre, quand il est rempli, c’est parfois une liste parfois un tableau associatif. Par exemple, pour les articles et les rubriques, ça me renvoie :
[
0 => [
'type' => 'rubrique',
'champ' => 'id_rubrique'
]
]
Et pour les mots, ça me renvoie :
[
'type' => 'groupe_mot',
'champ' => 'id_groupe'
]
Est-ce que c’est normal cette différence ?
Réponse à moi-même : sûrement la même raison pour laquelle les enfants mangent les frites avec les mains
A priori, ce n’est pas possible de faire des surcharges par squelette comme dans collection_json (ou alors je n’ai pas trouvé comment faire). Par contre, j’ai facilité la création de nouveaux types et de nouvelles requêtes pour un développeur
Voir ce commit.
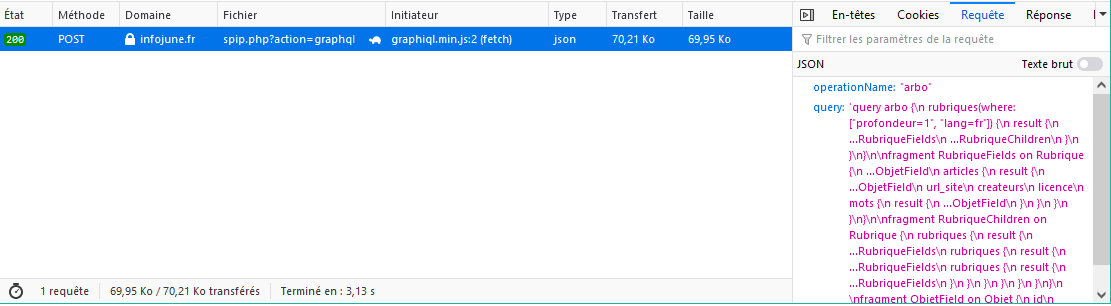
J’ai fixé un petit bug ce matin. Le plugin est en production sur https://infojune.fr/spip.php?action=graphql
Voici une requête graphQL qui permet de récupérer toute la hiérarchie du site :
query arbo {
rubriques(where: ["profondeur=1", "lang=fr"]) {
result {
...RubriqueFields
...RubriqueChildren
}
}
}
fragment RubriqueFields on Rubrique {
...ObjetFields
articles {
result {
...ObjetFields
url_site
createurs
licence
mots {
result {
...ObjetFields
}
}
}
}
}
fragment RubriqueChildren on Rubrique {
rubriques {
result {
...RubriqueFields
rubriques {
result {
...RubriqueFields
rubriques {
result {
...RubriqueFields
}
}
}
}
}
}
}
fragment ObjetFields on Objet {
id
titre
descriptif
logo
maj
rang
}
Tu donnes l’url du site et ce que tu indiques être une requête graphQL.
C’est parce qu’avec ces éléments, on peut tester et voir ce que ça donne ?
Dans ce cas pourrais tu STP citer texto une requête http simple mais non vide, qui fait quelque chose et le montre ?
Ah mais apparemment il faut une requête POST…
Merci @JLuc de t’intéresser à graphQL avec SPIP ![]()
Tout à fait. De plus cette requête montre toute la puissance de GraphQL pour générer des requêtes complexes.
Pour tester des requêtes graphQL, tu peux bien sûr faire du curl et construire les en-têtes toi-même. Mais il existe des clients déjà tout faits ![]() (j’en parle dans la doc du plugin). Tu peux par ex installer une extension pour ton navigateur. Pour Firefox, j’utilise Alltair. Dans le client, il suffit de saisir l’URL du endpoint à interroger et une requête afin de visualiser la réponse. Grâce à ce type de client, tu peux aussi parcourir le schéma d’introspection du endpoint pour découvrir les types et les requêtes disponibles afin de créer tes requêtes.
(j’en parle dans la doc du plugin). Tu peux par ex installer une extension pour ton navigateur. Pour Firefox, j’utilise Alltair. Dans le client, il suffit de saisir l’URL du endpoint à interroger et une requête afin de visualiser la réponse. Grâce à ce type de client, tu peux aussi parcourir le schéma d’introspection du endpoint pour découvrir les types et les requêtes disponibles afin de créer tes requêtes.
Effectivement. GraphQL fonctionne avec du POST :